


We live in a world governed by fast results. Caching is one such technique that enables rapid responses online. This begs the question for software engineers:

How do we determine the best design for our cache such that it fits the needs of our application while staying reliable?
When it comes to system design for caching, there are two approaches a software engineer needs to consider. There is the in-memory cache system, versus the distributed cache system.
- in-memory cache system
- distributed cache system
In-memory cache system
An in-memory cache is a data storage layer reliant on a single computer's main memory (ex: random access memory, or RAM). The in-memory cache sits in between applications and databases and provides responses with lightning speed. The system accomplishes rapid responses by storing data from prior made requests or by storing data copied directly from databases. The RAM used for temporary storage is known as the cache.
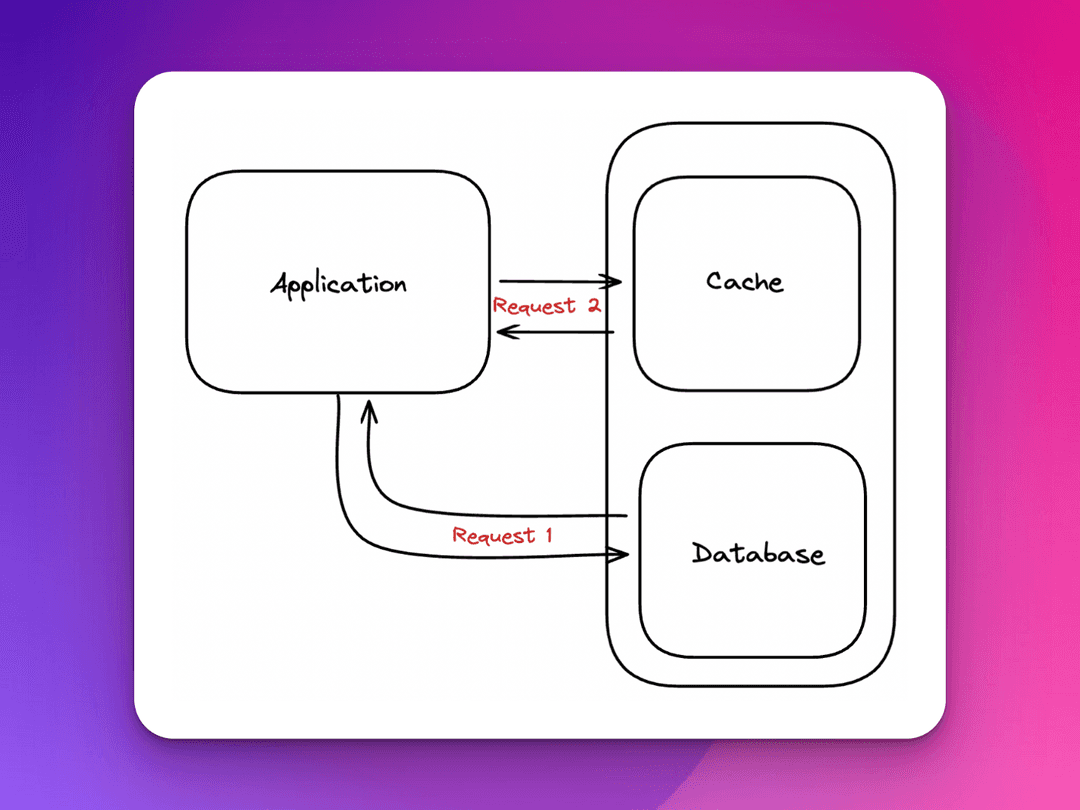
The important piece to note in my explanation of this type of caching design system is the specification that the in-memory cache is reliant on a single device’s memory. If you’re questioning which device the cache lives on, this could be a client-side cache (in the browser or hosting application of the client) or a server-side cache (some arbitrary server that sits between the application and the database).
We now need to take into account the pros and cons of using a cache and the different types of caches we can leverage.
A few pros to using a cache:
- Latency reduction
- Accelerated data retrieval
- Increase IOPS (Input/Output operations per second)
However, it’s the detriments to caching that we want to focus on when considering the in-memory caching system. The potential risks associated with relying on an in-memory cache encourage a software engineer to consider whether a single device will be sufficient for their application needs, or if they need a more involved system.
The primary concerns a good engineer needs to consider with in-memory caching, and really any system design-related problem:
- Scalability
- Availability
- Performance
Scalability

Memory on a single device is a limited resource. Consider the burden we may be placing on our single device if we intend to cache large datasets or have our device single-handedly manage an application with a high volume of traffic. We will inevitably see performance-related problems begin to bubble up with an overburdened cache. When that time comes, one can infer it is time to scale their cache system to better meet application demand.
Availability
It may occur that our connection to the cache is severed. Without our cache, the system becomes unresponsive, leading to a poor user experience.

Meeting the availability requirements means focusing on ensuring that the data in the cache is not lost or inaccessible during hardware failures.
Performance
As an application grows, so does the demand for a caching system. If the caching system is neglected, application performance begins to see a negative impact.
High performance is the first priority for any caching system, as performance is the entire point of creating a cache in the first place!

If we start to see issues arise in any of these three points, we need to consider making our system more robust and scalable. In comes our distributed caching system design to the rescue!
Distributed Cache System
A distributed cache is a design system that pools together the memory resources of multiple networked computers into a single in-memory data store. A distributed cache enables us to break out of the limitations of a single computer. This strategy of sharing data across multiple computers by accumulating their processing power is also known as a distributed architecture or a cluster.
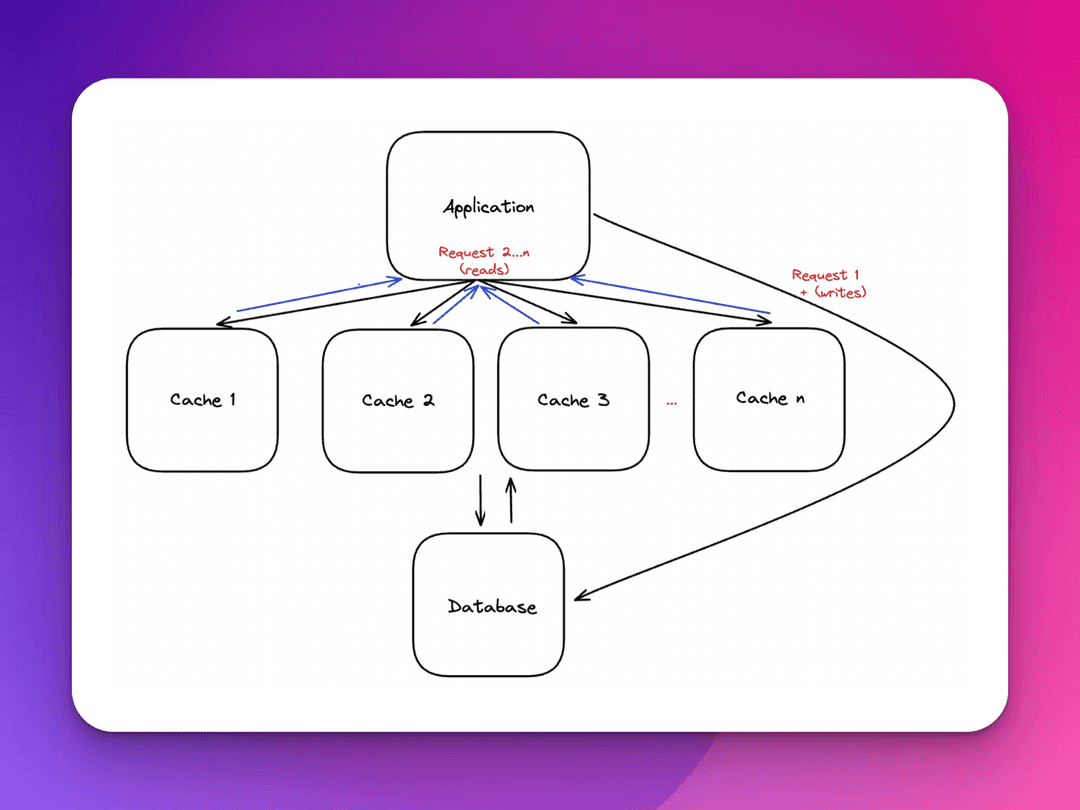
An analogy to consider for a distributed cache is to think of the system as a brain and the individual computers as the limbs that listen for the brain’s command. Each server or limb doesn’t know of the others, nor does it have to. Each is responsible for its own function and no other. Recognize with this analogy that each individual computer in the overarching system or the “big picture” is abstracted out, and managed at a higher level.
An operation of this scale comes with its set of challenges. The primary challenge with a distributed cache design system is determining what rules govern the split of the data. Determining partitions for datasets is challenging as the never-ending trade-offs with each approach challenge the engineer's critical thinking.
One concept for implementing a distributed cache system is sharding.
Sharding involves breaking up the data into horizontal or vertical partitions, also known as the horizontal or vertical scaling of a system. Each partition is referred to as a shard or an individual server.Now sharding in databases may be familiar. Database sharding and caching systems both leverage the same approaches and balance similar tradeoffs when considering data segmentation.
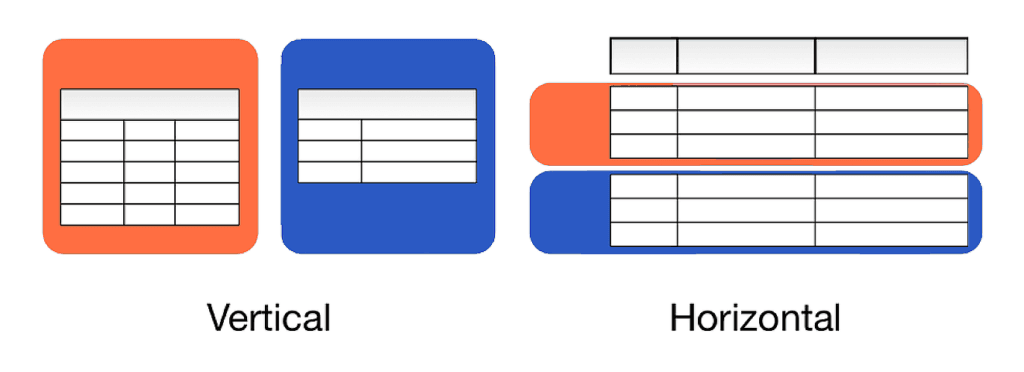
A few data sharding approaches:
- Geo-based sharding
- Range-based sharding
- Hash-based sharding
Each data sharding approach has its own advantage and disadvantage.
Geo-based sharding
This concept of sharding is based on location, more specifically, the user's location. The user gets matched to a server or node closest to their location.
The benefit of geo-based sharding is a reduction in latency. However, the population distribution by location varies, leading to unbalanced partitions, making this a downside to this approach.
Range-based sharding
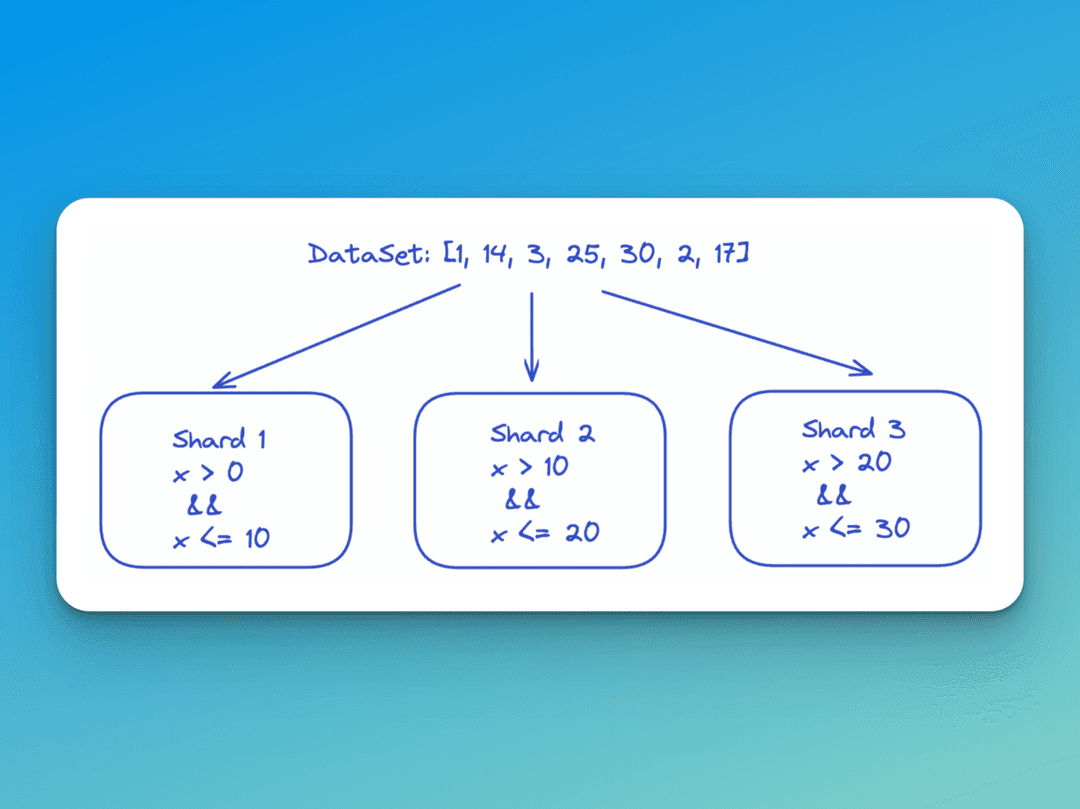
Range-based sharding sections off data by a range of the key value pair determined by the engineers.
One popular example where range-based sharding comes in handy, which also conveniently is a popular interview question for software engineers, is for the handling of word searches.
Given a list of millions of documents, how would you find all documents that contain a list of words?
This question is so common in the interview setting, that it was even covered in the famous Cracking the Coding Interview Series book. Any software engineer that doesn’t own this book is putting themselves at a disadvantage. All of the fundamental concepts of the software engineer's job are covered, with ample thought-provoking questions per topic, caching included. Each question is subsequently answered with correct and optimal solutions by the author herself, a prior Google engineer that conducted hundreds of technical interviews and was on the panel.
Now I won’t go into how this question specifically is implemented, you can refer to the Cracking the Coding Interview book for that! However, you can imagine how the alphabet e.g: [A-Z] could serve as an appropriate range to define our partitions.
The nature of range-based sharding makes it easy to add more partitions or machines as it does not require extensive intervention from engineers. However, the disadvantage to sharding poses the risk of a potential hotspot caused by non-uniformly distributed data. One segment of the range could become responsible for far more hits than others.
Hash-based sharding
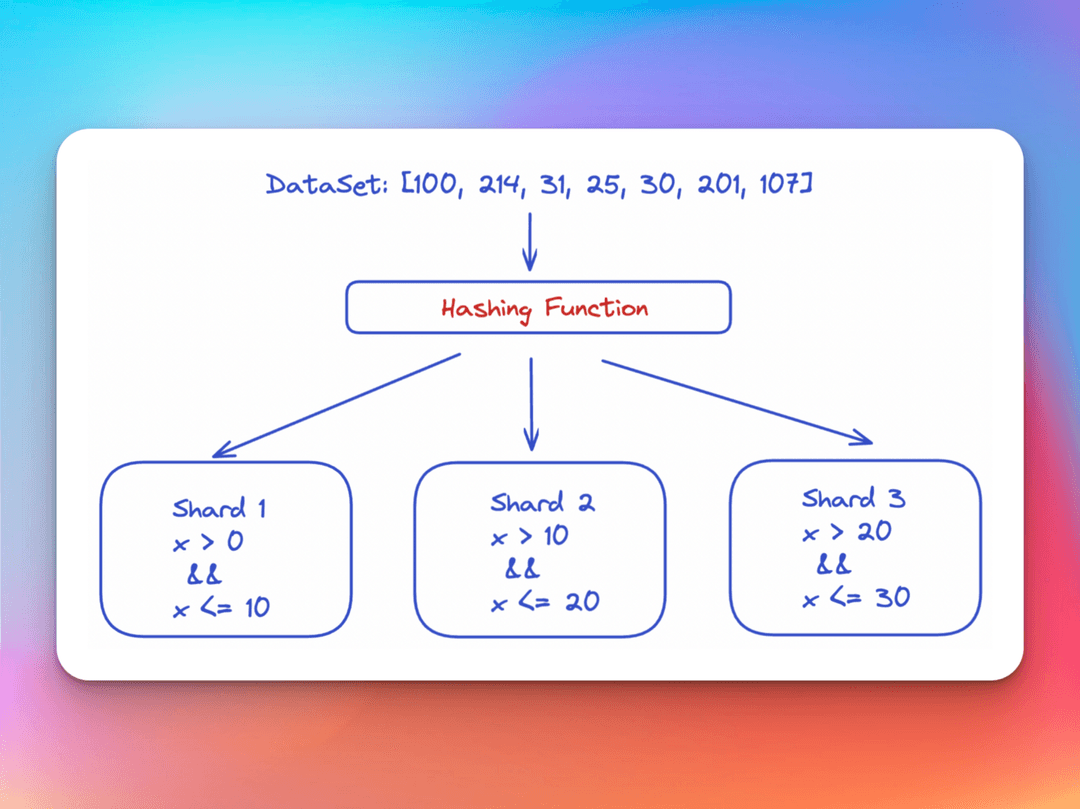
Hash-based sharding runs the input keys for the cache system through a hashing algorithm. The hash value is used to compute the appropriate partition, thereby allocating the result to the appropriate bucket. This is demonstrated through the above image, as we have values in the dataset that are larger than our defined ranges. Our hashing function maps these values to fit in the appropriate slots.
A good hash algorithm will distribute data evenly across partitions. However, it is blind to relations in the data, thereby missing the opportunity to improve performance by trying to predict and pre-load future queries.
Cache Writing Policies
Once an engineer has determined how best to partition the data given the use case, the rest of the cache is about the implementation details and engagement of the cache with the application and database.
A few of the diagrams in this post demonstrate that the application can still end up going to the database in instances where the cache does not contain the relevant data. And in the system design decisions have been made for some caching behaviors, particularly around how writes get handled.
These decisions came from the following questions.
- How will the cache be obtaining the data it needs to serve to the application?
- How does the cache avoid containing irrelevant data, better known as cache inconsistency, in the occurrence of writes?
Techniques to avoid irrelevance of cached data, or avoidance of cache inconsistency is coined by cache writing policy or the expected behavior of a cache while a write operation is being performed. A cache’s write policy plays a central and critical part in the varying characteristics exposed by the cache.
Cache writing policies are covered in an upcoming article that will focus on the design process of caches as well as the implementation details of a caching system.
Summary
An in-memory cache design system is a data storage layer reliant on a single computer’s main memory. Given the in-memory cache depends on a single device, it is potentially a temporary solution for an application that does not involve unreasonable demand on a single device.
The way we justify unreasonable demand on a single device serving as our in-memory cache design system is by evaluating:
- Scalability
- Availability
- Performance
Once one begins to see tell tale signs of the single device becoming overburdened with the workload, one needs to expand their singular device to become a node aiding a more sophisticated network of devices. This network of devices is known as a distributed cache system.
A distributed cache system requires thorough thinking of the engineers. Working with a network of devices poses the challenge of how best to partition or shard the data in order to effectively share the resources of the multitude of devices.
Make sure to follow through and learn about the different types of caches to bring your cache knowledge full circle!
Remember, developers are creatures that turn coffee into code. So I'd very much appreciate if you bought me a coffee! 
We post relevant topics in the tech industry with a specific focus on web development biweekly on Monday’s. Join the ByteSizedPieces newsletter to stay on top of free relevant topics!
Thanks for reading again! ❤️
| Understand Open Graph Dynamic Image Meta Tags | 1 |
| Pros and Cons of Caching Data in Software | 2 |
| How to build a Modal in ReactJS (Part One) | 3 |