

Caching intimidates developers of all skill levels. However, despite its challenges, caching is an important concept a developer should devote the time to wrap their minds around.

When applied correctly caching can bring about dramatic improvement to applications and servers of the like.
Caching has several pros and famous cons that make it an area that software engineers tend to approach with reluctance. Prior to diving into the types of caches, there are cases to caching a developer first needs to understand.
A software engineer should understand the following about a cache.
- What is a cache?
- Why is caching important?
- Pros of caching data
- Cons of caching data
What is a Cache in Software Development?
A cache is a sophisticated data structure intended to store information, usually data, temporarily in a computing environment. Simply put, a cache is a temporary storage structure for information that has already been seen.

Why is Caching Important?
Caching data is important because it enables applications or servers to quickly retrieve data that has already been seen. This means caching helps speed up application performance while additionally increasing efficiency.
A cache is valuable as it enables us to salvage precious computing power. Instead of re-retrieving data, we have already seen we retrieve it from the cache. Talented software engineers distinguish themselves from others by seeking and acting on opportunities that optimize their work in areas that add value. Caching is one such opportunity for high value.

Compute power and memory strike a delicate balance. Oftentimes the cross-comparison of CPU preservation vs memory tests an engineer's situational awareness. Caches aren't always the optimal solution, but knowing when to use a cache and how best to implement a cache system makes for a powerful developer!
Pros of Caching in Software Engineering
Advantages of caches:
- Retrieve content faster for applications, ex: websites
- Improve application performance
- Accelerate data retrieval (decrease time duration for queries)
- Reduce latency of database querying
- Reduce the load on backend services
- Reduce database cost
- Reduce CPU usage
- Enable predictable performance
- Increase IOPS (Input/Output operations per second)
- Improve user experience (faster load times = happy consumer)
- Content is still available in network issues
- Save device energy
Believe it or not, this long list contains just a few of the reasons a cache should be considered in software engineering efforts.
Let's expand on some of the above points for why caching should be considered for applications.
Caches reduce the load on backend services
Caches redirect parts of the read load from the backend database to the in-memory layer. Because caches are stored in memory, caches naturally reduce the load on databases. The latency of database querying improves because our databases have fewer queries to address.
Fewer database queries tie into the point that caching decreases database expenses as well. Less database querying means less cost!

Finally, if we reduce the returns to the database, we decrease the strain on our databases, meaning they're better protected! Databases are subject to crashing at times of unexpected spikes. Traffic spikes are naturally balanced out by caches, as fewer queries end up going back to the database.
Enable predictable performance for applications
Traffic spikes in application usage can come in expected time periods. An example involves increased traffic to college basketball pages for sports websites when March Madness comes around yearly. Another example of traffic spikes engineers can anticipate applies to e-commerce sites during Black Friday or scheduled sales. To combat traffic spikes while reducing costs, developers can choose to lean on a cache.
Increased load on databases results in higher latency to retrieve data in web development. The application performance rapidly becomes unpredictable as engineers encounter these uncommon scenarios. A high throughput in-memory cache mitigates the risk as caches preclude the increase in traffic from making a mark on databases, ensuring applications behave in predictable manners.
Improve Application Performance
Those with Computer Science or Engineering backgrounds know that CPU Usage and Memory Usage are constantly at odds. We learned that storage tends to be slower than memory, as a result, we need to exercise caution when relying on storage.
The engineer's aspiration involves spending as little computing power as possible while achieving the fastest results without too much reliance on storage. Therefore working with a cache requires trade-off evaluation.
Fulfillment of this goal may be tough if an engineer lacks the understanding of RAM vs Disk. Let's dive into the components we need to understand, which in turn will help us see how powerful a concept caching is.
Random access memory (RAM) vs Disk
RAM (Random access memory) has a conveniently fast path to the computer's CPU. The disk is much slower given our CPU has to determine where the long-term data is actually being stored. As a result, memory access is substantially faster than reads from disk.
Databases tend to use disks to store our data. The line of thought for disk storage versus memory comes down to the longevity of our data persistence. If the data is something we want to keep for a long period of time, it's better stored on disk. This is why database reads can be slow and should actively be avoided if possible!
Reduction in the necessity of database reads and reliance on memory means we get our data faster, which in turn means our application performs better. Significantly faster data access improves the overall performance of the application.
In-memory systems tie into an increase in IOPS or Input/Output operations per second. One instance of a single in-memory data store used as a cache has the potential to serve hundreds of thousands of requests per second. Let's break that down into ms to see the dramatic time improvement caching brings to the table.
Your average RAM chip accesses memory in 10 nanoseconds. Disk Access Time is the sum of Access Time and Data Transfer Time.
Disk Access Time = Access Time + Data Transfer Time
Access Time is defined as the amount of setup time needed to read from the right segment of the data block.
Data Transfer Time is defined as the time it takes to transfer the found data between the system and the disk.
Disk Access Time is the sum of Access Time and Data Transfer Time, resulting in an average 25–100 milliseconds time duration for disk data retrieval. Let's evaluate disk retrievals via the best-case scenario, 25 milliseconds.
Recall earlier I mentioned your average RAM chip accesses memory in 10 nanoseconds. We already can see a major difference when we compare 10 nanoseconds for memory access to 25 milliseconds for disk access (1 nanosecond is 0.000001 milliseconds)!
But let's press on. We are comparing 100,000 requests made to disk versus memory.
100,000 requests to memory would take 1,000,000 nanoseconds or just 1 millisecond.
100,000 requests to disk would take 2,500,000 milliseconds.
Compare 1 millisecond to 2.5 million milliseconds! That is the difference we are discussing when we propose using caches (memory access) to database access (disk).
Recall additionally that I chose the best case scenario for the time it takes to retrieve data from the disk. This means that retrievals of data from disk can only get worse.
Caching when done right can turn a bog of a system into a snappy little vixen, and we just saw the proof in numbers!

Cons of caching in software engineering
Some disadvantages to caching:
- Storage consumption
- Risk of outdated content (stale data)
- Incorrect or corrupt cached data
- Security risk
- Cache invalidation is difficult
- Overhead and Complexity
- When the device turns off cache is lost
Notice that although the list is shorter for disadvantages to caching, they are serious. If the software engineer responsible for implementing a cache doesn't strike the right balance, we can be in trouble with an application misrepresenting our data or posing security vulnerabilities.
How about we discuss some of these disadvantages of caching data?
The risk of outdated content or stale data
The premise of using a cache in solutions and caching revolves about retaining prior retrieved data. We force data we pulled a certain time period back to "stick around" for longer. In doing so, software developers pose the risk of presenting data that is old. We don't necessarily know that this data stored is dated because we do not go back to the database to retrieve what's been updated.
Let's proceed with an example of how our cached data can become outdated or stale.
Popular E-commerce sites like Amazon or Warby Parker get millions of page views daily. These visits could mean an abundance of database queries for products that the software engineers decide could be cached.

Let's say the software engineers decide to update their cache system once a day.
It should go without saying that at least one of these products is subject to change within 24 hours. We can also agree that any alteration to a product should show up immediately on an E-commerce site. Imagine a product goes on sale 2 hours after the cache has been updated. A consumer wouldn't see that sale on the product until 22 hours pass and the cache gets updated!
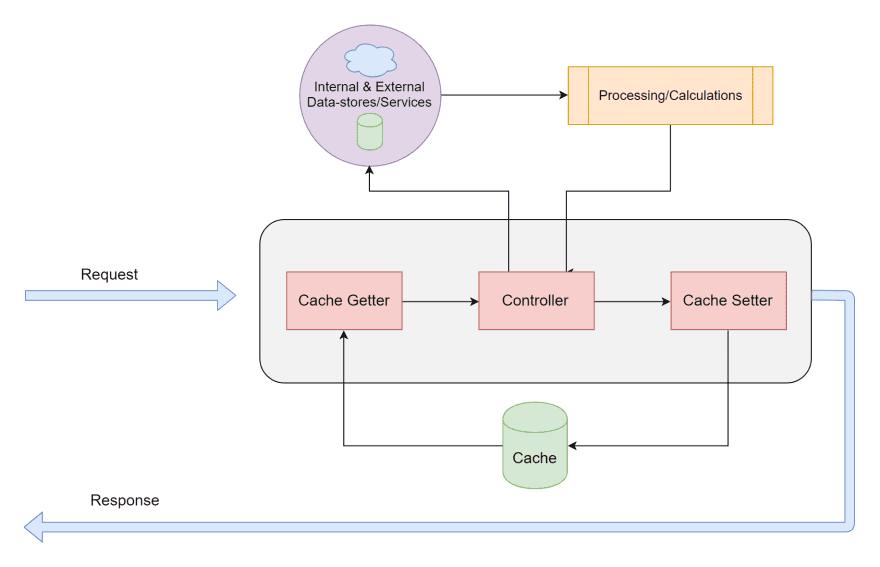
With the e-commerce example, we observe the necessity for caution when using a cache system. Software engineers need to be considerate about choosing when the cache is deemed invalid and in need of updating.
My above scenario now becomes one revolving around the concept of cache invalidation. Software engineers need to consider the following question.

Perhaps instead of 24 hours, our team of software engineers for e-commerce sites decides to bring the cache invalidation timing down to a matter of a few seconds.
Now we ask again the same question.
If the product manager updates the pricing of a product, is it acceptable that a consumer receives that update a few seconds later?
Now we get to the famously challenging part of caching, as the software engineer's situational awareness is put to the test.
Consider the following cases for the second cache invalidation idea: Is the product a time-sensitive sale, or always an offering on the website? Do these particular products have high visibility and lots of traffic that could impact large sums of users?
Perhaps if the product is time sensitive, or has the potential of being time-sensitive, then maybe even a few seconds is not good enough for cache invalidation. If the product is always an offering on the website, a few seconds is not the end of the world. In cases of high visibility and traffic, perhaps a few seconds would not be doable for purging the cache. It becomes far more likely that a large volume of users will receive this outdated information.
The demand for in-depth reasoning, careful consideration, and meticulous information gathering of cases makes decision-making for caches a genuine challenge for software engineers.

Overhead and Complexity
The balance software developers need to strike to avoid stale data while improving application efficiency and performance is in fact overhead. Working with a cache can become far more complex if they go by methods besides timestamps, which makes it harder for developers to maintain the code written and understand the source of problems if they arise.
Engineers typically rely on a variation of problem-solving methodologies to avoid these potential issues, but naturally, such alternative methods introduce even more complexity. Again, situational awareness is key. Engineers need to understand the implications of the decisions they make, for the sake of both users and their own coworkers!
Summary
Bear in mind that a little can get you a long way. Don't let what-if scenarios bog you down and deter you from huge performance gains. Consider usage of a cache for your solutions.
In summary:
The main benefits of using a cache are:
- Reduction of load on backend services
- Predictable Performance
- Application Performance Improvements
The potential cons associated with caching:
- Outdated/Stale data
- Poor choices for cache invalidation
- Overhead and Complexity
Happy caching everyone!
Remember, developers are creatures that turn coffee into code. So I'd very much appreciate if you bought me a coffee!  I’m a new writer and I will be posting very frequently on my findings and learnings in the tech industry and beyond. Join my newsletter if you would like to stay tuned!
I’m a new writer and I will be posting very frequently on my findings and learnings in the tech industry and beyond. Join my newsletter if you would like to stay tuned!
Thanks for reading again! ❤️
| Understand Open Graph Dynamic Image Meta Tags | 1 |
| How to build a Modal in ReactJS (Part One) | 2 |
| Email automation with Firebase Mail Extension and SendGrid | 3 |